Age Annotations Dataset
The Age Annotations Dataset is a crowdsourced annotation dataset with known ground truth values, which is collected for the purpose of evaluating crowd-labeling methods. Apart from consensus estimation, this dataset can be used in a multitude of ways in machine learning and artificial intelligence research. If you use this dataset in your work, please cite the following article:
(2015). Modeling annotator behaviors for crowd labeling, Neurocomputing, 160, 141-156.
Collection of this dataset was funded by "Multimodal Computational Modeling of Nonverbal Social Behavior in Face to Face Interaction (SOBE), SNSF Ambizione Fellowship Project".
Annotated Data (the FGNet Aging Database)
We asked the annotators to annotate the samples of the FGNet Aging Database* which consists of a total of 1002 pictures with known age values from 82 subjects. Some samples from the FGNet Aging Database: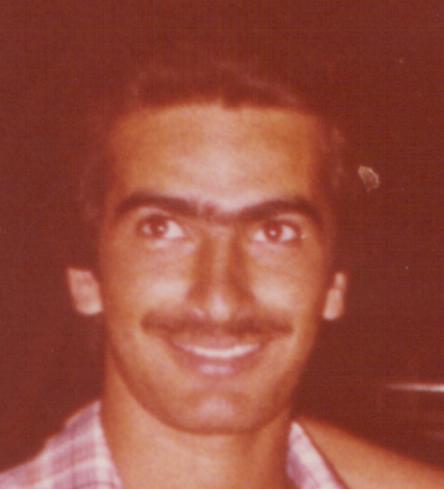








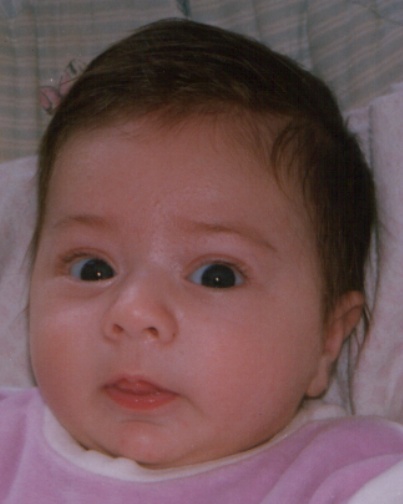
(*) Lanitis, A. (2008). Comparative evaluation of automatic age-progression methodologies. EURASIP Journal on Advances in Signal Processing, 2008, 101.
Annotation Task
For the annotation task, we prepared a questionnaire in which we show a facial picture and asked the annotator to rate the age of the person in the picture. The annotators were asked to rate the age from 1 to 7 where a lower rate means young and a higher rate means old. The following figure shows the annotation task instructions shown to the annotators:

Annotation statistics
The table below shows annotation counts for these two sets and their joint set. The table describes the frequency of annotators' annotations. For example, there are 208 annotators in Set 1 that have provided 10 annotations and there are 292 annotators in Set 2 that have provided 15 annotations. It can be seen that not all of the annotation counts per annotator are multiples of 10 or 15. This is because the system decides to collect fewer annotations when the "5 annotations per sample" criterion is met.| Annotator workload |
Number of annotators | ||
|---|---|---|---|
| Set1 | Set2 | Joint | |
| 1 | 2 | 4 | 6 |
| 6 | 0 | 1 | 1 |
| 7 | 1 | 0 | 1 |
| 9 | 2 | 0 | 2 |
| 10 | 208 | 0 | 208 |
| 11 | 1 | 0 | 1 |
| 14 | 1 | 0 | 1 |
| 15 | 0 | 292 | 292 |
| 16 | 0 | 1 | 1 |
| 19 | 1 | 0 | 1 |
| 20 | 82 | 0 | 82 |
| 29 | 1 | 1 | 2 |
| 30 | 26 | 12 | 38 |
| 31 | 1 | 0 | 1 |
| 33 | 0 | 1 | 1 |
| 36 | 1 | 0 | 1 |
| 40 | 5 | 0 | 5 |
| 42 | 0 | 1 | 1 |
| 43 | 0 | 1 | 1 |
| 45 | 0 | 1 | 1 |
| 50 | 3 | 0 | 3 |
| 59 | 0 | 1 | 1 |
Download
There are seven files in the archive:
- age_groundtruth.csv: Defines the groundtruth values for the samples. Each row of the file has
semi-column separated ground truth values, respectively, as follows
- sample id
- the age of the person
Sample rows from the file SampleID Age 001A02.JPG 2 001A05.JPG 5 001A08.JPG 8 ... ... - age_annotations.csv: Defines the annotations of the samples. Each row of the file has
semi-column separated annotation values, respectively, as follows
- id of the annotator of this annotation
- id of the sample of this annotation
- age annotation
Sample rows from the file AnnotatorID SampleID Age 17513083 080A06.JPG 3 23818111 080A06.JPG 1 3056891 070A12.JPG 1 24182981 070A12.JPG 1 22502301 049A08.JPG 4 ... ... - age_annotations_set1.csv: Similar to age_annotations.csv, but only for the first set
- age_annotations_set2.csv: Similar to age_annotations.csv, but only for the second set
- kara2015cl.pdf: The paper introducing this dataset
- kara2015cl.bib: BibTeX database for the above paper
- readme.txt: A copy of these descriptions