Head Pose Annotations Dataset
The Head Pose Annotations Dataset is a crowdsourced annotation dataset with known ground truth values, which is collected for the purpose of evaluating crowd-labeling methods. Apart from consensus estimation, this dataset can be used in a multitude of ways in machine learning and artificial intelligence research. If you use this dataset in your work, please cite the following article:
(2018). Actively Estimating Crowd Annotation Consensus, Journal of Artificial Intelligence Research, 61, 363-405.
Collection of this dataset was funded by "Multimodal Computational Modeling of Nonverbal Social Behavior in Face to Face Interaction (SOBE), SNSF Ambizione Fellowship Project".
Annotated Data (Head Pose Image Database)
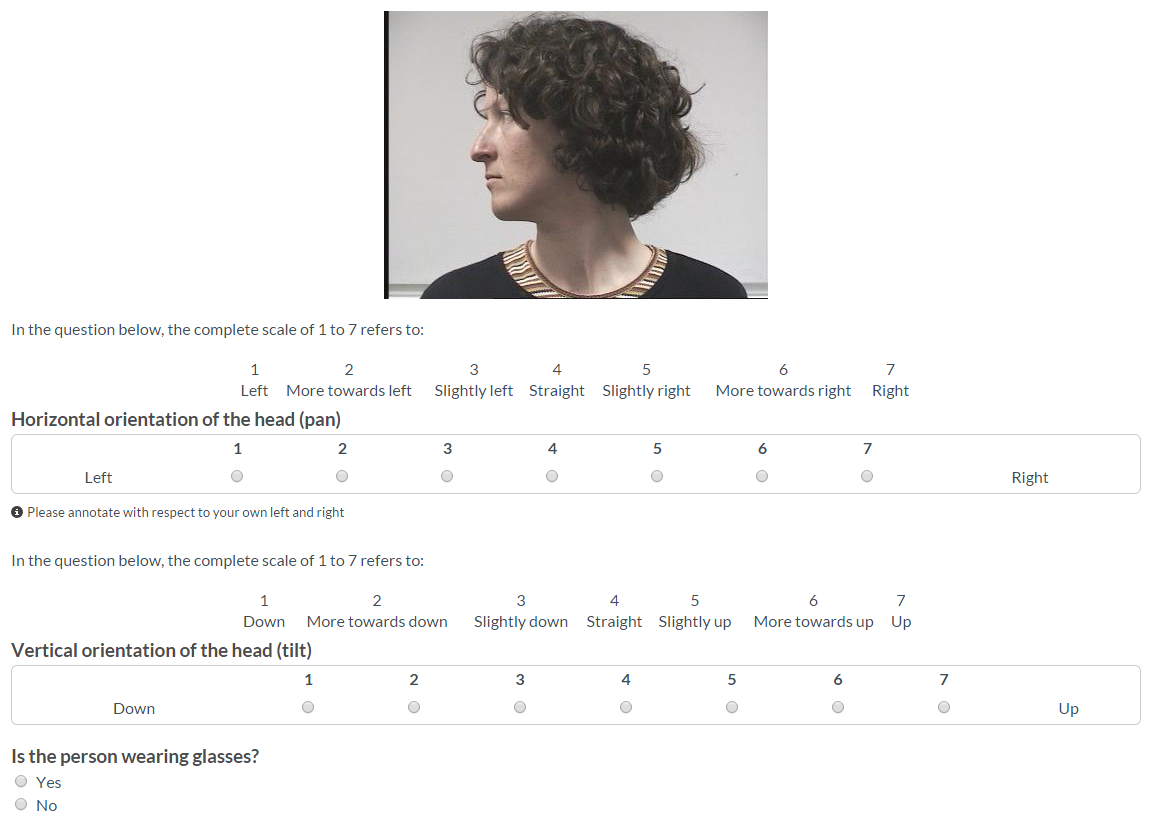
We asked the annotators to annotate the samples of the Head Pose Image Database*. The dataset has both "pan" and "tilt" ground truth values for a total of 2790 photos. The "tilt" values in the dataset are {-90, -60, -30, -15, 0, +15, +30, +60, +90} degrees and the "pan" values are {-90, -75, -60, -45, -30, -15, 0, +15, +30, +45, +60, +75, +90} degrees. The pan-tilt pairs used in the dataset result in 93 unique head pose configurations. There are two series of photos in which 15 subjects portrayed all of these configurations. 6 subjects in the dataset wear glasses in one of their photo series. Some samples from Head Pose Image Database:(*) Gourier, N., Hall, D., & Crowley, J. L. (2004). Estimating face orientation from robust detection of salient facial features. In ICPR International Workshop on Visual Observation of Deictic Gestures.
Annotation Task
Due to budgetary constraints, we submitted only a subset of these images to the CrowdFlower (rebranded as Appen) platform for annotation. We chose only one photo series for each subject. If available, we chose the photo series with glasses, otherwise the first series was used. We tried to choose a balanced combination of images with and without glasses. For pan and tilt values, we chose the photos with {-90, -60, -30, 0, +30, +60, +90} degrees in both dimensions. A total of 555 photos were annotated. For each photo, we asked the participants to annotate three questions:- Horizontal Orientation (pan): Left(1)-Right(7) (annotators' own left and right)
- Vertical Orientation (tilt): Up(1) - Down(7)
- Whether the person is wearing glasses or not.
Annotation statistics
In the table below, we present the annotation frequency of the samples. Out of 555 samples, 475 have 9 annotations, with other samples having as few as 7 and as many as 17 annotations.| Sample annotation count | 7 | 8 | 9 | 15 | 16 | 17 |
|---|---|---|---|---|---|---|
| Number of samples | 10 | 10 | 475 | 6 | 34 | 20 |
| Annotator workload | 5 | 10 | 17 | 20 | 24 | 30 | 39 | 40 | 45 | 50 | 55 | 60 | 70 | 75 | 80 | 84 | 90 | 100 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Number of annotators | 1 | 61 | 1 | 45 | 1 | 26 | 1 | 15 | 2 | 13 | 1 | 7 | 5 | 1 | 4 | 1 | 2 | 2 |
Download
There are five files in the archive:
- headpose_groundtruth.csv: Defines the groundtruth values for the samples. Each row of the file has
semi-column separated ground truth values, respectively, as follows
- sample id
- whether the person is wearing glasses or not,
- tilt orientation angle of the head
- pan orientation angle of the head
Sample rows from the headpose_groundtruth.csv file SampleID Glasses Tilt Pan person01100-90+0.jpg yes -90 0 person01101-60-90.jpg yes -60 -90 person01103-60-60.jpg yes -60 -60 ... ... - headpose_annotations.csv: Defines the annotations of the samples. Each row of the file has
semi-column separated annotation values, respectively, as follows
- id of the annotator of this annotation
- id of the sample of this annotation
- glasses annotation
- head tilt orientation annotation
- head pan orientation annotation
Sample rows from the headpose_annotations.csv file AnnotatorID SampleID Glasses Tilt Pan 29899677 person05111-60+60.jpg yes 4 4 29899677 person09120-30+0.jpg no 3 4 28962469 person15179+60-90.jpg no 6 1 28976121 person15179+60-90.jpg no 6 1 28962469 person01116-30-60.jpg yes 3 2 ... ... - kara2018acl.pdf: The paper introducing this dataset
- kara2018acl.bib: BibTeX database for the above paper
- readme.txt: A copy of these descriptions